I am writing my Master’s thesis on Ardour, more specifically I want to see whether there is any speedup in making in-track plugin parallelism as opposed to running them in different tracks. To do this, I have to understand how latency is propagated through routes and when latency changes (I m guessing plugin config/different I/O config etc.). I am not planning on trying complex routing schemes, I just want to do simple examples like a parallelised plugin route vs. 3 routes with sends and receives and see if there’s any improvement (if any). Can any of the developers explain what I have to look for?
3 Likes
Unless I misunderstand what you are describing, in-track plugin parallelism is not possible. If you have 3 plugins A, B and C, plugin B cannot run until plugin A has run and so on. The only way you could parallelize is to split the buffer into smaller pieces, but that generally slows things down, rather than speeding things up.
If the actual buffer size is very large, then potentially splitting the buffers so that A can run on some part of it, then B can get started, might show a minor speedup. But most people don’t run with buffers of a size where I’d expect this to work this way.
There are other issues with “speed” and plugins in Ardour that have nothing to do with parallelism. The amount of work we have to do on every buffer processing cycle before we even get to call into the plugin is (at least superficially) mind-boggling.
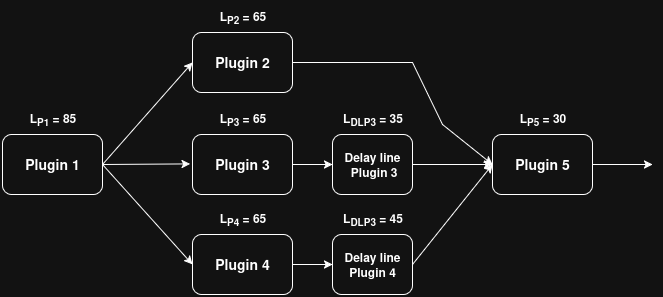
Thank you for the reply. What I was thinking was the following: say you have 4 plugins and the path would be like: A->B->D and A->C->D. Of course you could put C on a different route and connect it to A and D, but wouldn’t making an additional route more memory consuming than having A->B->D, A->C->D on the same route and spawning a thread (before playback) if a parallel task is possible? Putting a DelayLine on the path between B->D or C->D (whichever has lower latency) would then result in both of them relaying the data to D at the same sample. This is what I was referring to.
That’s very unusual to have one track’s signal being processed by two different plugins. You also need to combine the signal again for “D”.
I can think of two examples: parallel mono compression [1] and perhaps a cross-fade [2].
You’re right in that case B and C (two topmost plugin in the screenshots) could run in parallel.
However most producers would use a dedicated plugin that already does that internally instead of manually patching things that way.
Ardour uses a fixed number of process threads (usually one less than available CPU cores). Also keep in mind that Ardour always processes data (not just during playback): it’s a live mixer.
Ardour already adds a delayline when bypassing a signal “around” a processor (dashed line in the pin connection screenshots below - search for _delaybuffers in libs/ardour/plugin_insert.cc).
[1]
[2]
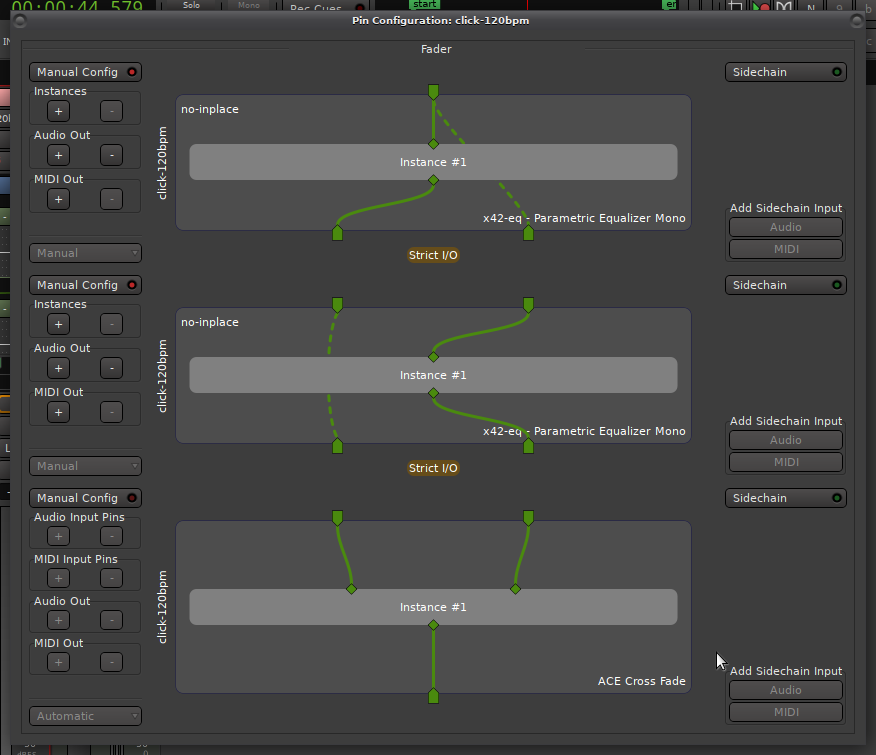
The current sequential processing of plugins (processors) in a route is in Route::process_output_buffers
initially the sample-position is offset by the total latency of all plugins in the route, and then it’s added back one by one in the loop:
I see. I was thinking what I proposed could have practical reasons, but I didn’t really think of it in terms of “yes it must be implemented”. As I am writing my thesis and having read bits and pieces of yours, I thought in-track parallel plugins could have UX and memory benefits (you don’t have to have a million tracks when you can have one which does the same thing as X tracks do - this is just a thought - and also you don’t have to initialise a whole route when you can spawn a thread when for example there aren’t that many routes to be used in so a thread is used in computing a plugin). This is more of a developmental experiment to see if we could achieve a little bit of a performance boost. Also, I didn’t really understand what you said about delaylines perhaps you can explain in a bit more detail? I have a diagram of how I thought of the latency propagation in parallel plugins.
If you are talking about plugin processing, this is what busses do.
Cheers,
Keith
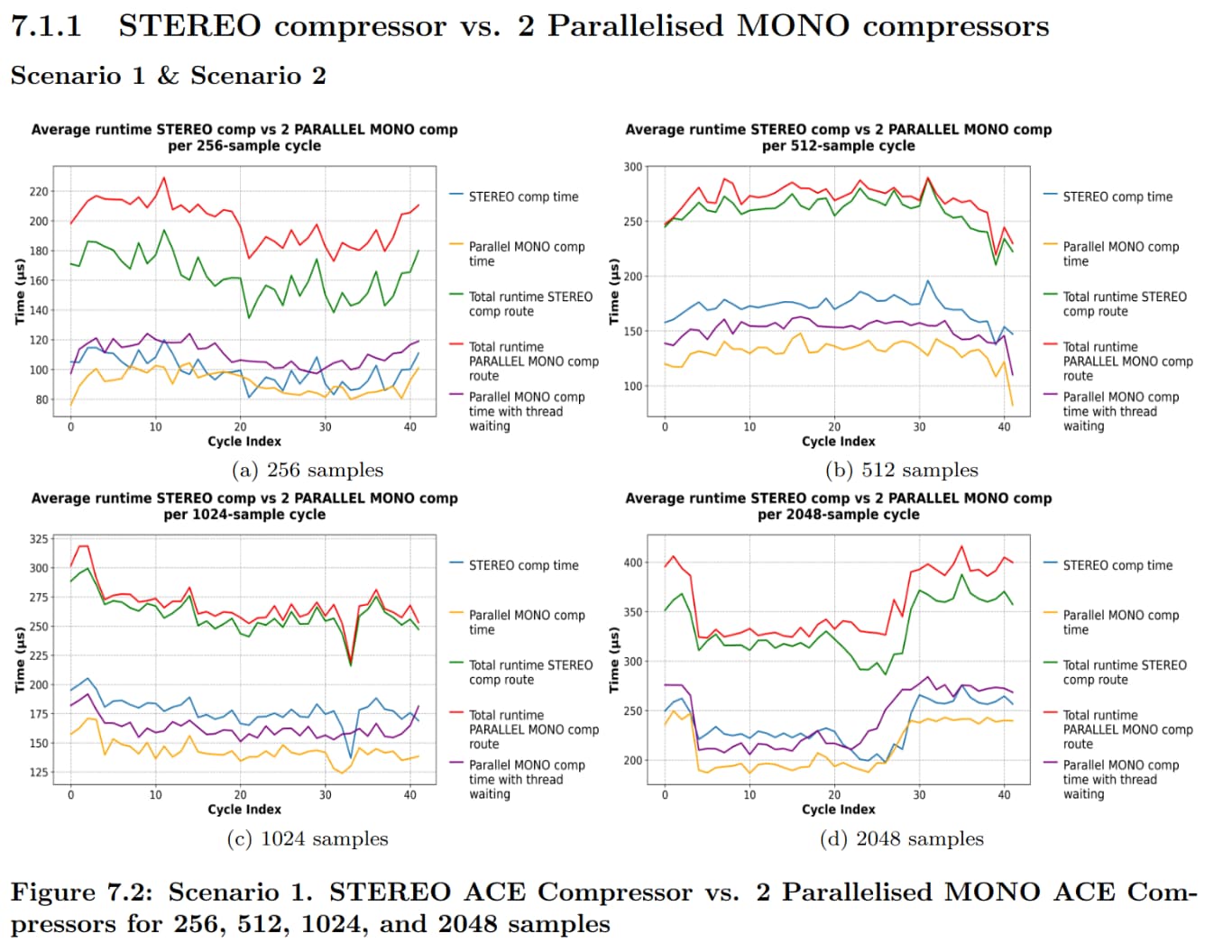
I have implemented the parallel version I was talking about previously (for my thesis), and I have a few discoveries, which Paul has basically predicted. The amount of speedup that can be achieved is of course limited by the overhead between threads and also atomic variable waiting etc. I want to have explanations for why I get the speedup in some cases and in some not and based on the plots (runtimes of aggregate cycles) and the code (for example of the x42 EQ plugin). The following are assumptions of what I think happens: For the x42 STEREO EQ, it’s processing channels independently, and thus at blocksizes <= 512 it’s better, but it’s performing worse at >= 1024 than the parallel version. Also, 2 MONO delays in sequence acting as a STEREO are worse than the parallel version for >= 256 blocksize. For the convolutional reverb, the parallel implementation is considerably worse given that it is doing FFT calculations and other things in parallel which amasses overhead and thus it’s not converging. I’m not sure what the explanation for the compressor is? Is the ACE Compressor STEREO running both channels simultaneously?
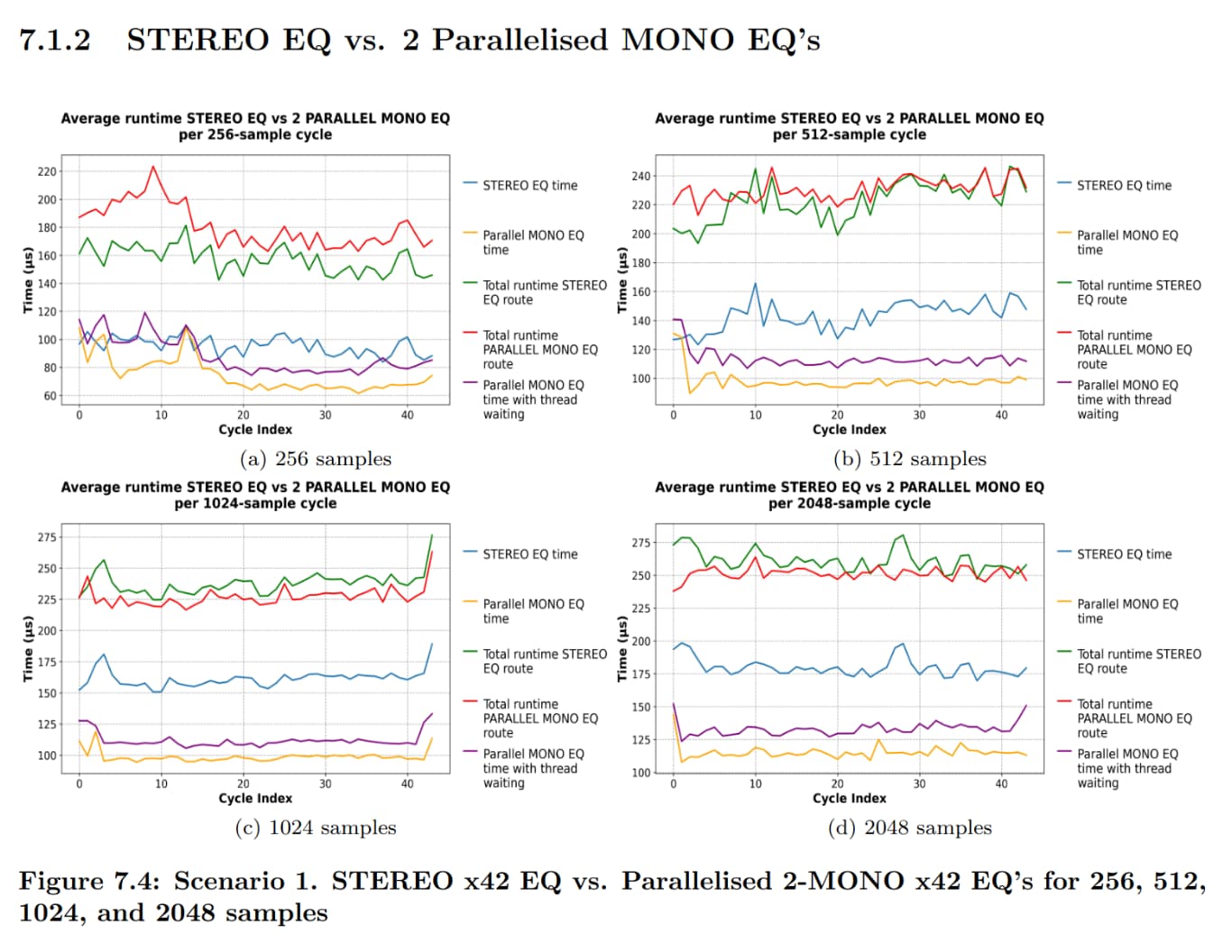
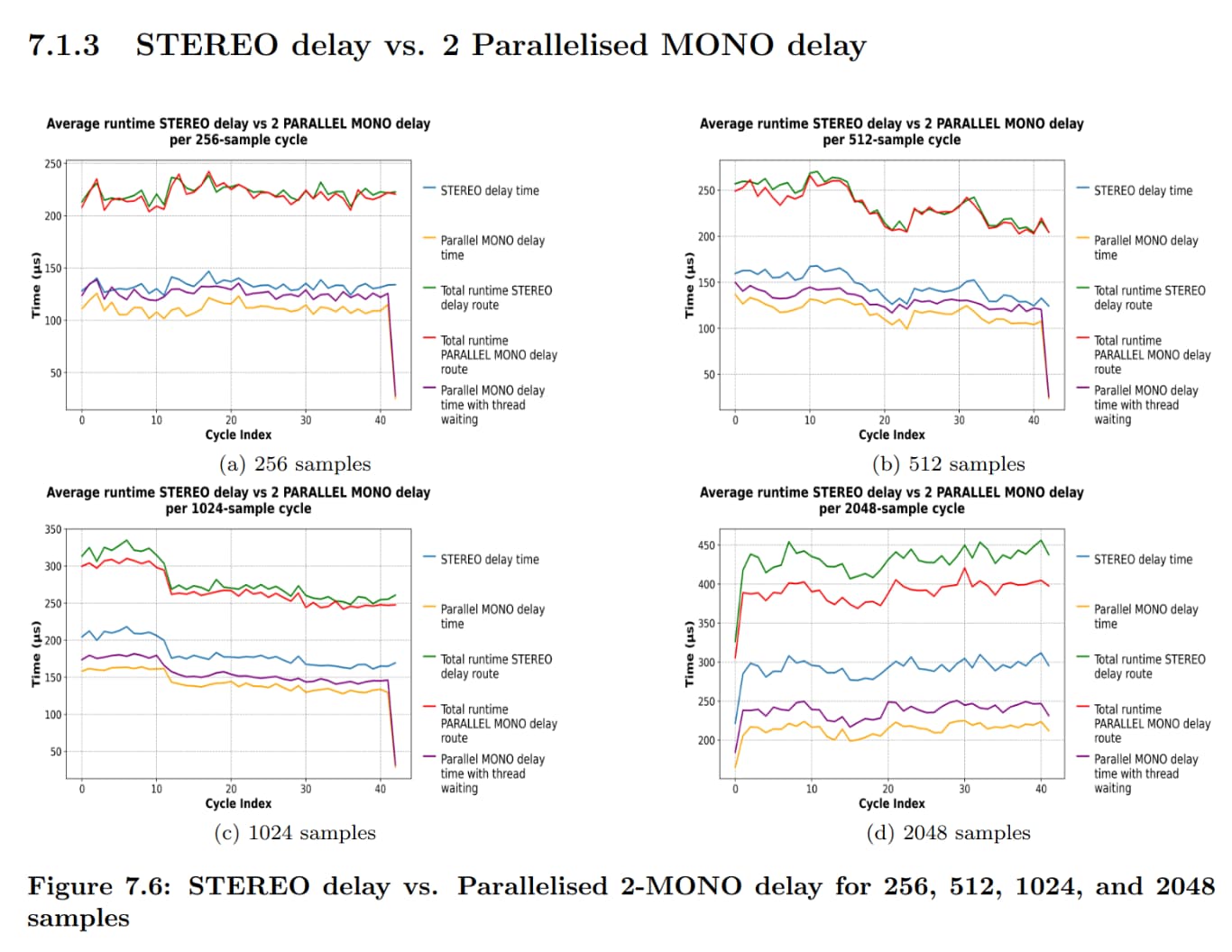
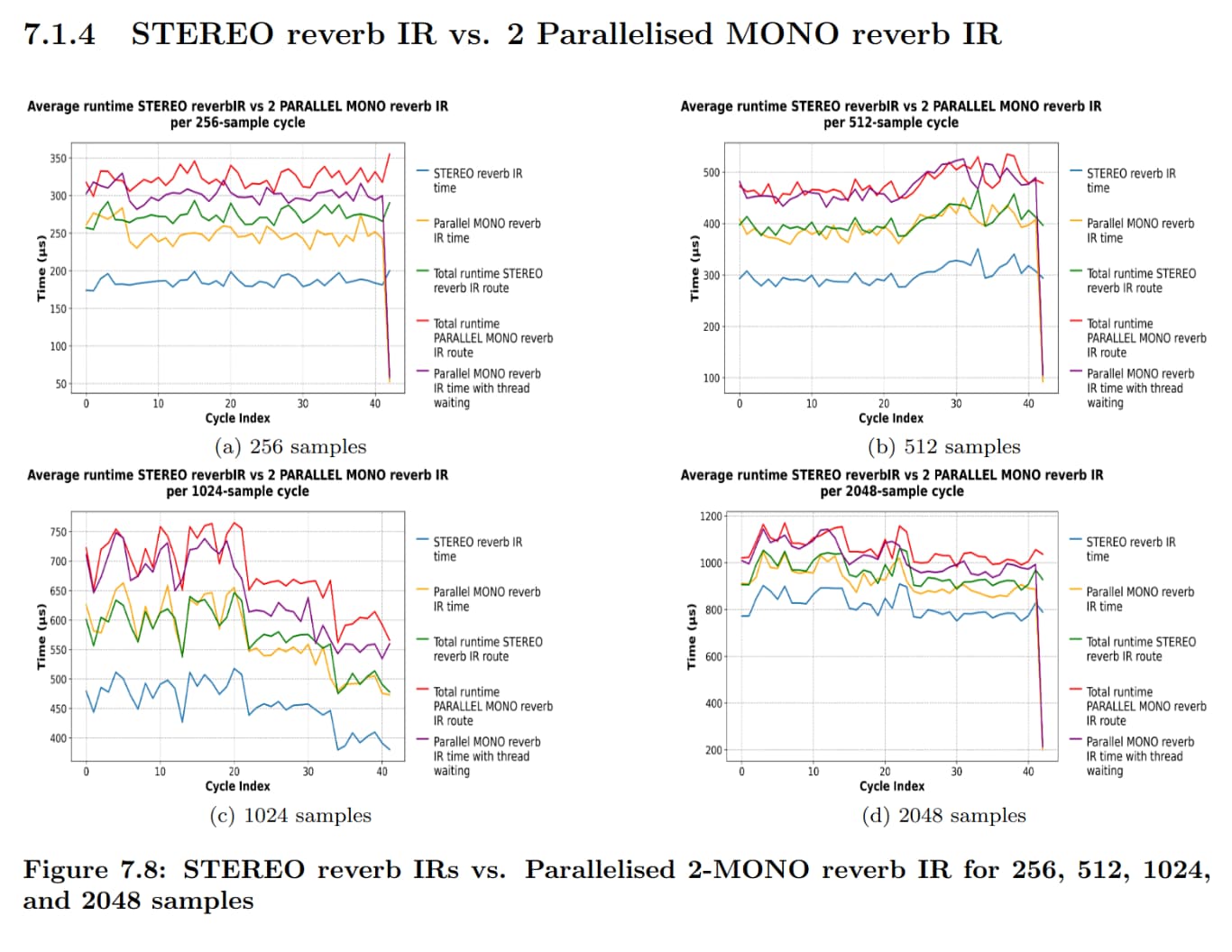
1 Like
Nice work!
Will your thesis be publicly available after your graduation?
I am curious about the general setup that you’ve used: How many CPU cores were available, and how many tracks did the Ardour session have that also processed in parallel, etc ?
Do you have an explanation why for the delay there is only a difference between stereo and parallel mono at a buffersize of 2048 ?
The overhead for stereo is minimal. Only at the very beginning the max of both channels is calculated [1], and at the end the computed gain is applied to both channels [2]. The expensive part of the computation is channel independent.
Also note that dual mono compression sounds differently than stereo compression. The same is true for Gate/Expander and most effects that are not linear time-invariant (LTI).
–
Really appreciate it.
Well, my implementation is kind of crude and the thread initialisation is hardcoded. In the initialisation phase after initialising the processors in the routes, I spawn an additional thread (for the track I aimed to test), which runs the helper function for running the additional parallelisable plugin.
In the frontend, more specifically ProcessorBox, I added a button which if >= 2 plugins are selected it marks them as parallelisable. (I added a few variables that help me with distinguishing what plugins are parallelised and with whom, see picture)
When the plugins are selected as parallelised in the frontend, a ProcessorGraph (the graph class I made) reorder is scheduled (handled in process_output_buffers), which takes into account the current_parallelisable and pending_parallelisable. The reorder also calculates the nr. of children and parents a processor has, which are necessary when waiting for dependencies (in the case of 1-to-N/N-to-1 cases). After the reorder, we add all the processors into our processor_vec for it to be iterated upon. (I made this extra vector to not confuse with processors_list). Also, after every iteration we need to re-initialise the parents, as we decrement them in every dependency run. Process seen in the picture.
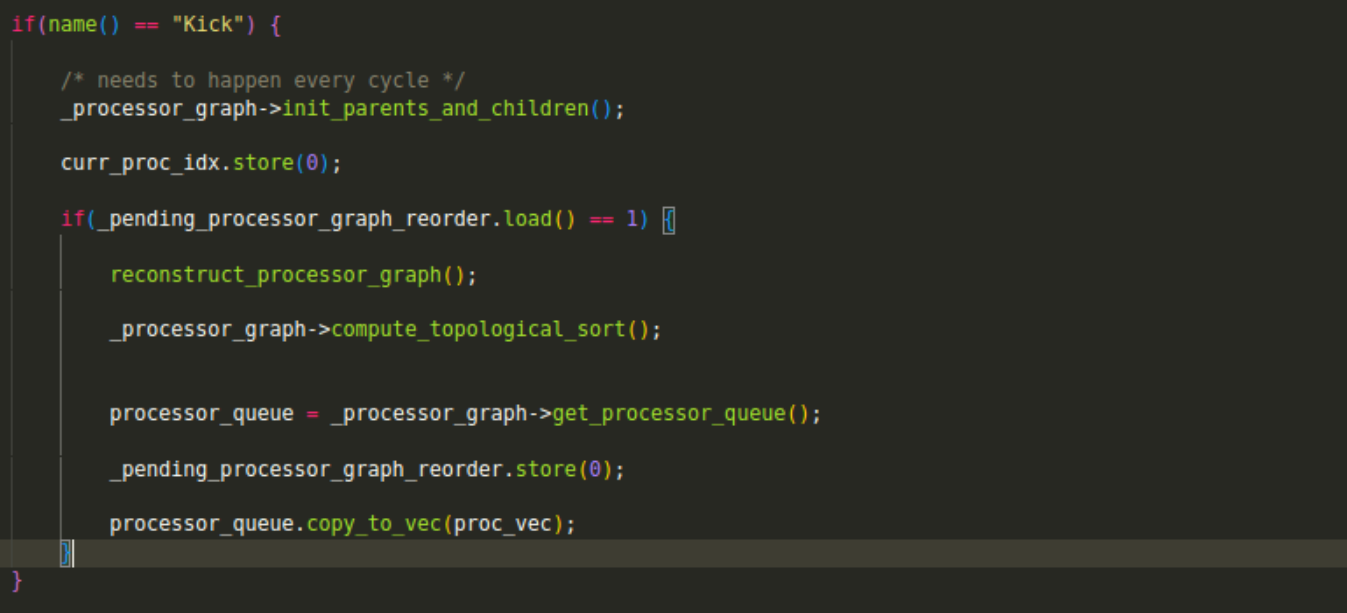
Now, in the meat & potatoes. To loop over the processors we use an atomic index. Every iteration we check if the index.load() != proc_vec.size() and proceed if so.
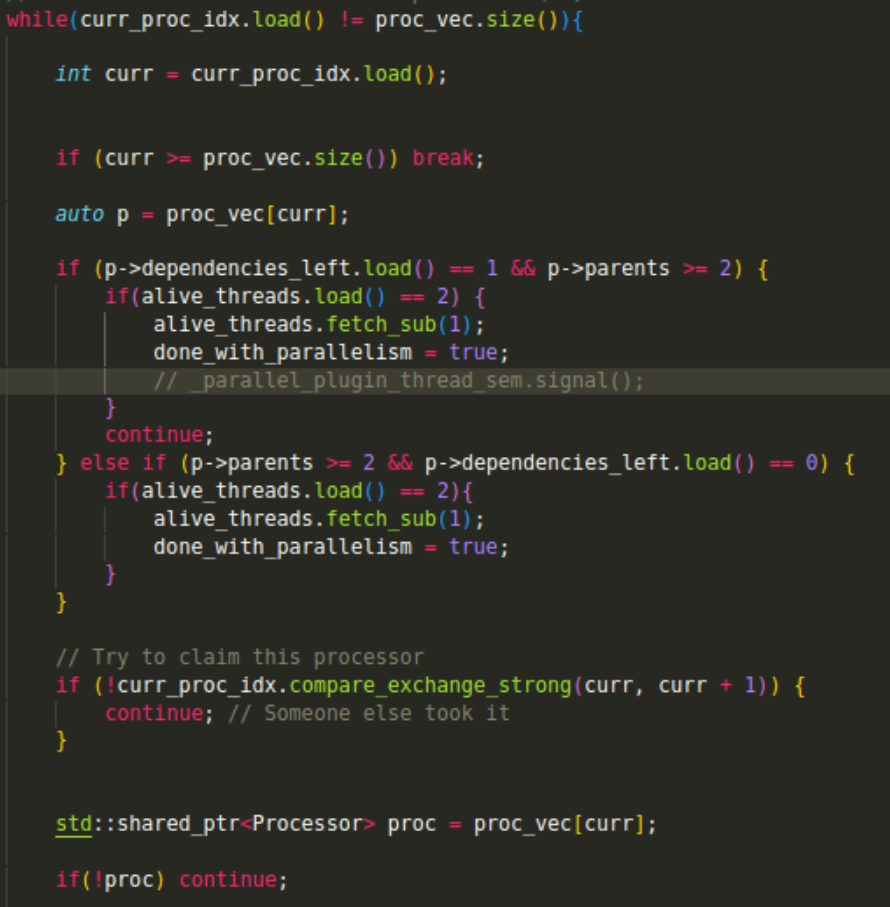
We take the processor at current index and we check whether it has >= 2 parents (parallelisable case) and if nr. of dependencies == 1 (we know that the other thread is working, so we goto while and decrement the nr. of awake threads to 1 - named very poorly “alive”, still haven’t changed it for some reason)
else if nr. dependencies == 0 then we just decrement the nr. of alive threads and proceed with the processor.
Of course we then need to check if the index has already been taken and only then start processing.
Latency propagation haven’t had the time to implement yet (should not be that complicated, but not within my scope for this thesis).
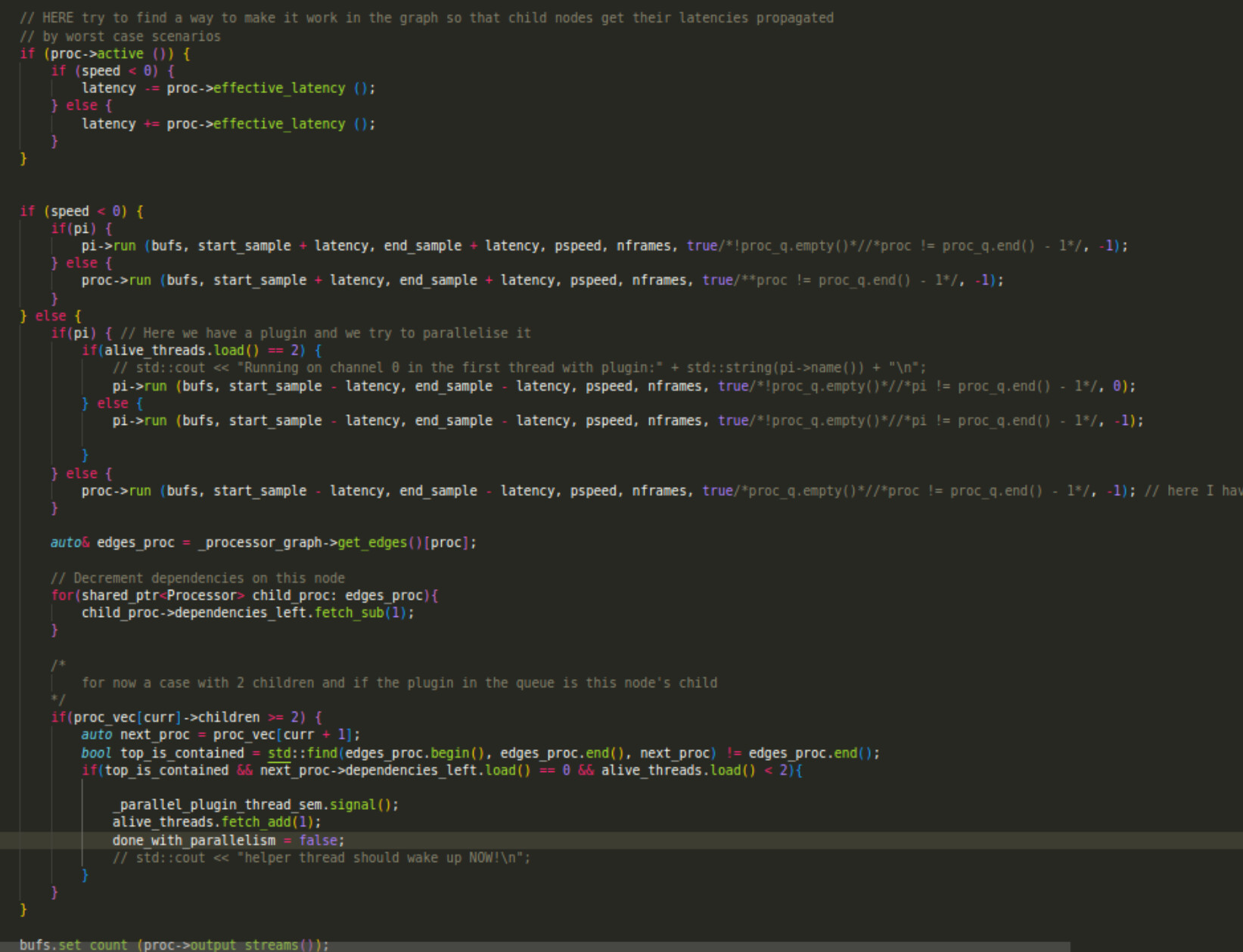
In the case of speed > 0, we first check if awake_threads >= 1 and if so, we process left buffer (I modified the processor function to include a channel index), ELSE we process it normally. After processor has executed we decrement its children’s dependencies.
At the end, we check whether the current processor has >= 2 children (we are in the 1-N case), AND if next_proc is the current’s child and if next_proc has no more dependencies (we have just decremented) and if awake_threads < 2 we signal the thread to wake up and increment awake_threads for later cases.
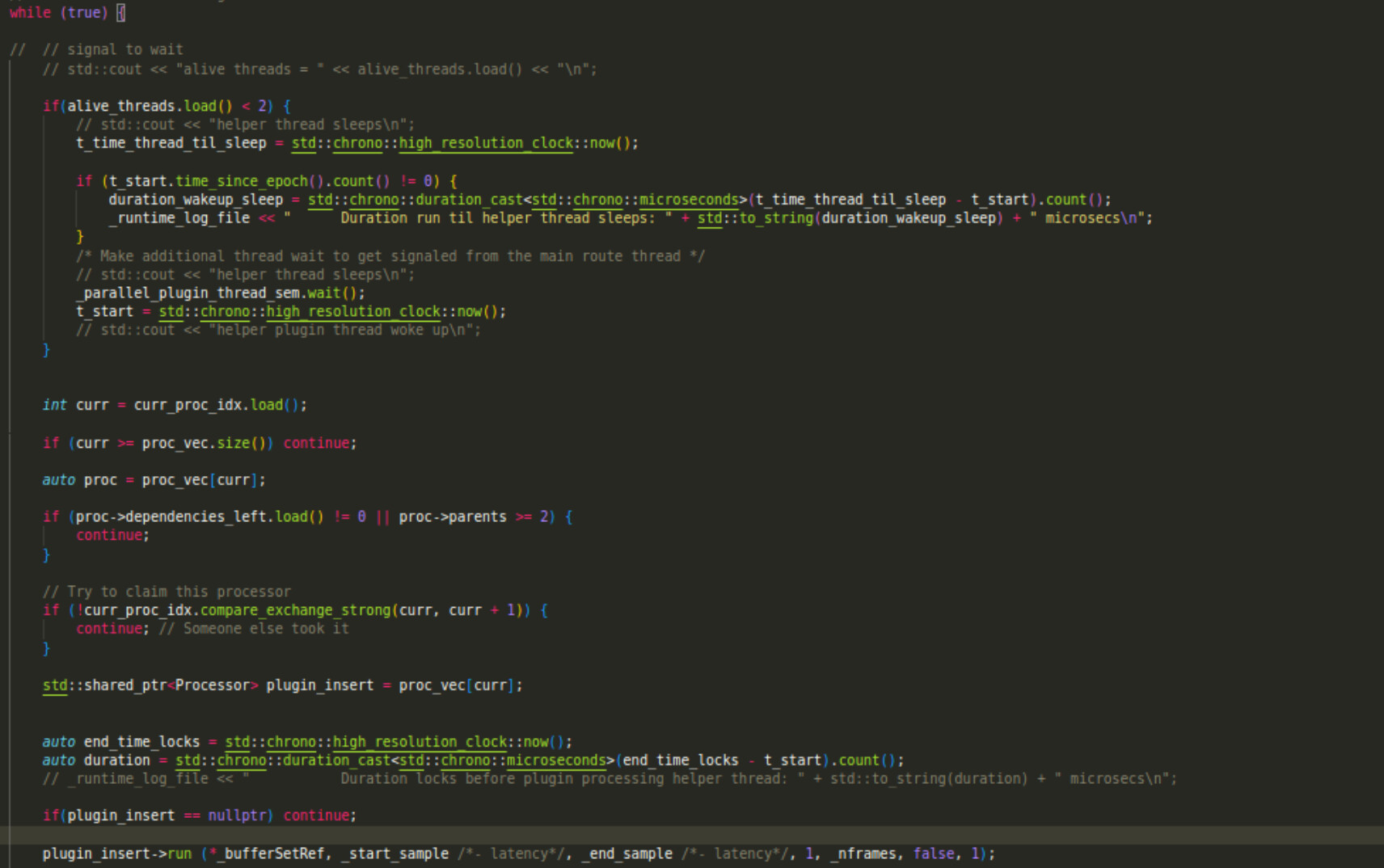
The helper thread looks very similar to this part of the function I explained.
Also, to make sure that the plugins can run on separate channels in a STEREO track, I have implemented this part in PluginInsert, which uses the channel index given in the function parameters to connect it to the plugin.
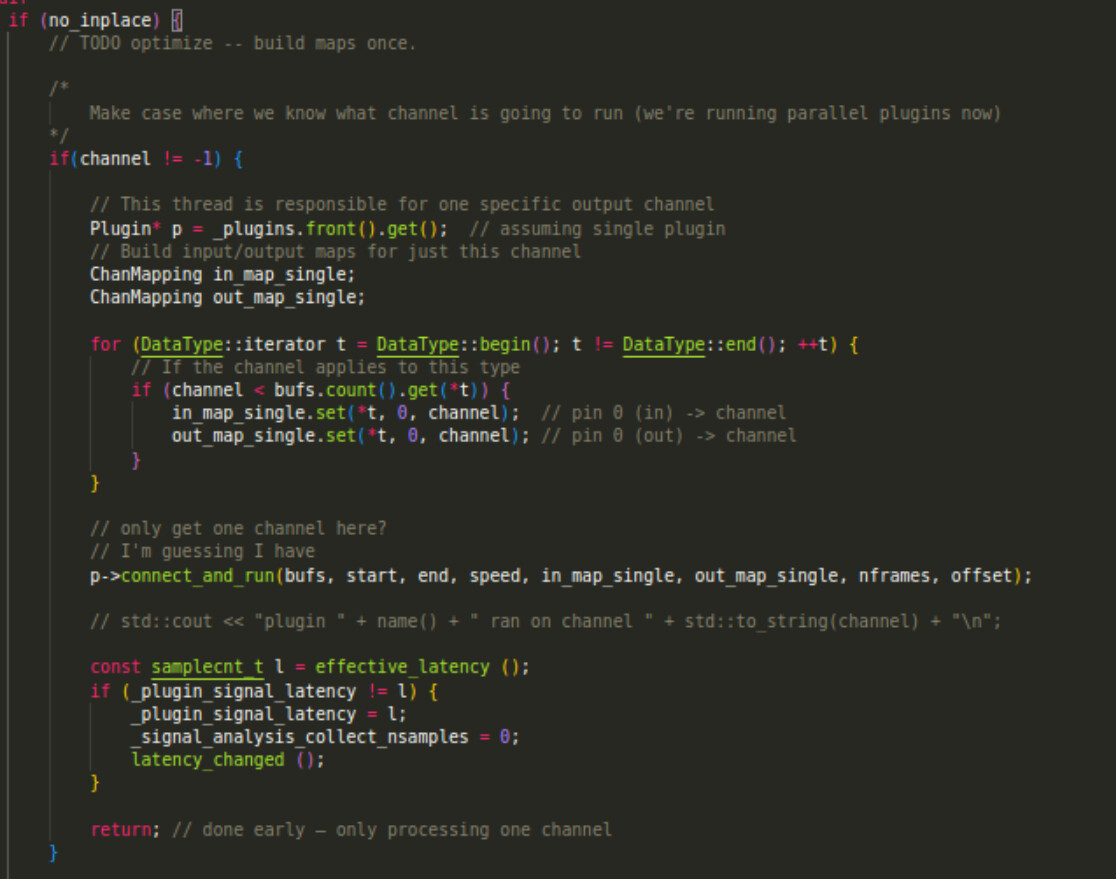
Now, I know this is a very Frankenstein-y way to code, but it worked for my needs. Hope this answers.
1 Like
Wow you did the whole thing, incl GUI. I didn’t expect that.
You may want to look into ARDOUR::RTTaskList and ARDOUR::IOTaskList which use a lock-free PBD::MPMC queue. In our case we found that synchronization overhead dominates for fewer than 3 parallel tasks (see RTTaskList::process). Yet your measurement shows that this is not always the case.
Those Tasklists use a thread-pool (configurable, up to the number of available CPU cores). I expect your approach would currently fail if you run more tasks in parallel than there are CPU cores.
Doing a quick/dirty prototype before implementing it properly make complete sense. As a very wise computer scientist put it: “plan to throw one away”.
Thanks Robin. Really appreciate what you guys are doing for the community. I’m not sure I will work more on the algorithm (at least for the thesis) as I have a limit of 3 months and it’s nearing to an end (I have 10 more days), and I have to finish writing the thesis, in which I also have an overview of Ardour: what the disk reader, disk writer, plugin insert do, the audio callback etc and they still need polishing. Do you think it would be useful to write a performance section on how the parallelised algorithm with 2 MONO plugins fares vs. the same MONO plugin in a MONO ? Just for informational purposes to see what the performance difference is?
About the thesis being published, I have thought about it. I am not really
sure what the process is, and I m kind of pressured especially with the
Ardour overview part where I very well could be wrong and missinform haha.
I’m pretty sure it’s gonna be available on the University of Amsterdam’s
website (they put theses there), but I m gonna talk with my supervisor
about the publishing. I also wanted to ask what is the policy of for
example putting an Ardour clone on someone’s GitHub? Is this possible?
Either way, I thought my idea could be helpful, but it’s rather slow in
some scenarios and you would need to basically change the implementation
only on specific blocksizes and plugins? It was a fun journey though. After
I m going to finish writing my thesis I will probably take a look and try
to make it faster.
Only if it’s relevant to the conclusion of the thesis… otherwise a 10 day deadline (with proof-reading, printing etc) might cut it close.
That’s what I meant. If the UvA has an online copy that’ll be great!
You could also pick a creative-commons license for it; and if you’re continuing your academic career, maybe present it at next year’s Linux Audio Conference (and get the univ to pay travel expenses ![]() )
)
Certainly, Ardour is licensed in terms of the GPLv2, so you can redistribute and modify it as you like. There are already many Forks · Ardour/ardour · GitHub
Veel succes met je scriptie.
–
PS. if you need someone to proof read, I could squeeze in a couple of hours next week. But if you don’t want to send it online before handing it in, I know an Ardour expert living in Amsterdam, too.
2 Likes
Ah, you are too kind. If you can proof-read that would be GREAT, as I don’t want to write something that’s not true in my Master’s thesis, especially because I am by no means an expert. (However much time you want is ok, I m thankful for you even considering). Ok so putting it on my GitHub as a fork is admissible that s great. Yeah I was thinking it is a pretty good addition to my CV as well. Sadly (or happily), I don’t think I will continue my academic career. This year was very stressful and the courses were rather meh. I never considered a PhD and it’s not within what I would want to do currently. Maybe in the future who knows?? I will start working in September, but I think I can try to optimize what I made for the thesis in the spare time that I have. Programming Ardour is super fun, especially if you’re a musician so you work on what makes you work haha. What astonishes me about Ardour is that it has a very rich feature set for an Open Source program. This requires quite some dedication, so I respect you guys a lot.
4 Likes
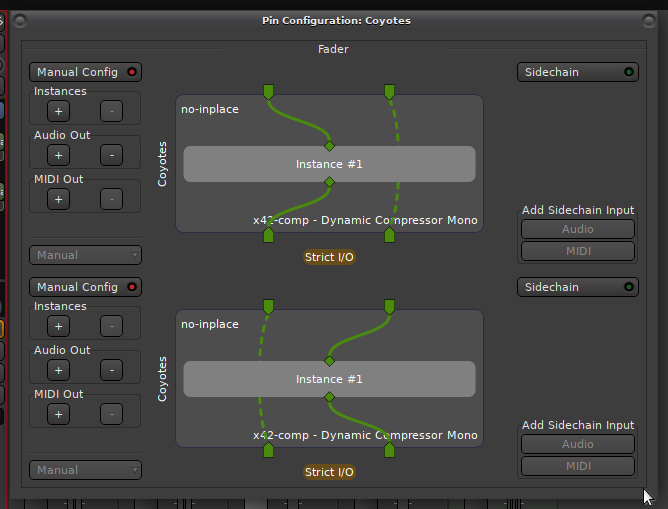
I am trying to explain the PluginInsert non-inplace and inplace cases, but I can’t find a generalisation. So inplace is basically when we have enough buffers to process, and non-inplace not, so we have the inplace_bufs, but it doesn’t always apply. After I tried several configurations in the manual configuration of the pluginInsert I have found the following:
-
inplace is when:
we have the #track channels = #plugin channels
we have #track channels < #plugin channels as we can split the first track channel into the remaining channels of the plugin
we have multiple plugin instances in the pluginInsert and there is no connection from the 2nd channel to anything -
non-inplace if:
#track channels > #plugin channels (some channels remain unconnected) OR
#track channels = #plugin channels (we have multiple plugin instances here) and in the manual configuration mode:
- the 2nd track channel has a connection with either input of plugin 2,3 etc.
- the 2nd plugin has a connection with the output channel
- there’s a bypass between any channel
My underlying confusion lies with inplace bufs. So inplace bufs would make sense as an addition when #track channels > #plugin channels, but when we initialise the processor chain we already made sure that the nr. of buffers is equal to max(#track channels, #processor channels) for all processors.
When the number of inputs to a processor (incl sidehain) is larger or equal to the number of its outputs, the same buffers can be used (input buffers == output buffers).
Only exception here is if you swap buffers (here L/R) or otherwise use no strict monotonic connections:
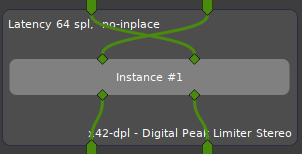
see PluginInsert::check_inplace()
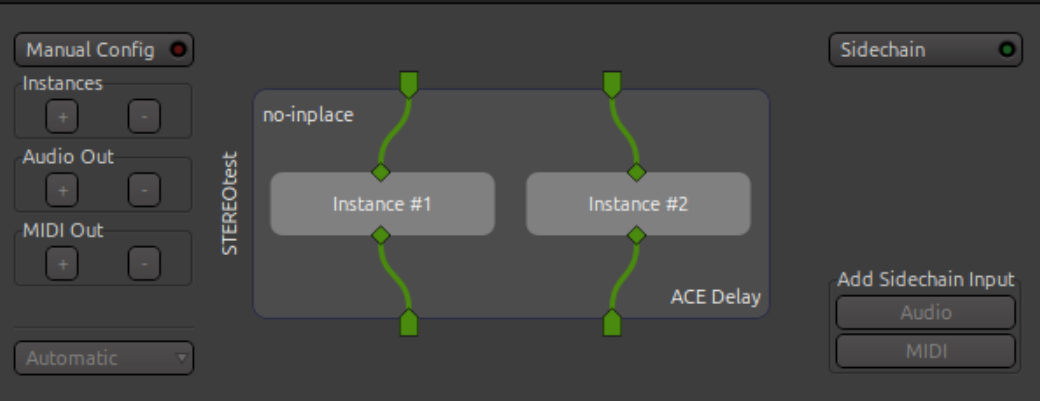
Yes, we should use in-place processing for those; likely the is_monotonic() check is too strict here and fails for the replicated plugin.
I see. Thanks a lot. I was banging my head against the wall here.