I want to create a one-man-choir sound using only one singer but recording that person 6-8 times per voice (tenor1, tenor2, bariton, bass). I know that it will not sound like an actual choir. This is actually intended.
My question concerns the workflow in Ardour.
I currently have two ideas how to do this:
Each recording gets a unique track. All tracks of a voice go to one bus (so I can do some voice specific EQing)
One track per voice and use overdubbing.
I am fairly new to producing music so I would be very interested, how you would tackle this. Maybe there is even a better solution I do not know?
One track for each ‘voice’ that is going to be part of the final project, so for instance if you want two tenors, that would be two tracks, or one tenor one bass, would be two tracks. I would then use takes/layered editing or playlists to comp down multiple recordings to make the voice as needed. I would EQ/process tracks as needed for the voice, then likely for your case buss down multiple tenor voices to a tenor buss so I could rebalance as needed easily or group process if needed.
hmm… I think this is not what I intended. The idea is to mix 6-8 recordings per voice so it would be like 6-8 people singing per voice. I.e. 6-8 overdubs per voice.
Just record your 6-8 voices on separate tracks and then as @seablade’s suggestion, route all voices of the same type to their own bus. The idea would be to balance all the individual tracks and then you can, for example, use the bus fader to adjust all tenors at the same time.
I’m about to do the same thing for a virtual choir performance of 50+ singers. As you point out, when using the same singer to record everything (I’ve done it myself) it won’t sound quite like a real choir but with some panning, reverb etc you should be able to make something that works.
I suspect that I (and maybe the OP) may need to creatively use differing reverb sends to add a sense of depth in addition to pan. I’ll be totally honest: I have yet to use VCA in my workflow but it’s probably about time I gave it a try
from what I read in the manual, a VCA is basically a bus without the ability to add effects. So what would be the advantage of using a VCA instead of a bus without adding any effects?
A VCA acts as a remote control for the input fader, and as @anon60445789 mentioned reverb (Which I almost put in my post but didn’t as I didn’t think it was answering your particular question) this is one area where it comes directly into play.
If you put your reverb on a seperate bus, and post-fader sends from your input channels to that bus (Or even from your busses/subgroups to that bus) and have the vca control the input channels. Assign a VCA to Tenors, Bass, Baritone, etc. on the input channel. Then when you bring the VCA down, it brings down all the input channels, and the send to the reverb (But not the output of the reverb, allowing the verb to tail off naturally) as well. Use the subgroup for group processing, use the VCA for mixing, it tends to work much better and easier (And is why and how it has been used in Live Mixing for so long, where it came from).
You can even get more complex with double VCA assignments, etc. but that is a topic for another time.
The way I usually do this (which is more often than I wish I had to) is :
Record several tracks for each voices (say 4 tracks of bass, 4 tracks of tenors1, etc). Try to sing each track within the same voice with a slightly different tone and also different microphones or at least, different placements (distance from mic and axis).
For each voices, slightly pan the 4 tracks and feed them to a stereo bus for processing. Use parallel reverb in that bus to simulate the depth of each individual track.
Pan the 4 bus (corresponding to each voice) the way I would want my choir to be and feed them to a master choir bus for processing. Apply reverb to now simulate the actual space in which to put that “fake” choir.
I’ve found Panagement, from AuburnSound, to be a fantastic plugin for those type of situations (it is cross platform but not open source though).
This is also how I record “fake” orchestra (strings and brass) when I only have access to one musician per voice.
Also depends on how dominant the choir will be in the final mix.
I once got 18 tracks from a kind soul in various voices done on an SmartPhone.
I created a separate Ardour project just to import and mix these 18 tracks based on a rough mix inported from the main project.
Then I exported a stereo track from this voice project and imported it back into the main project adding it to the other background voices.
Had to do one iteration at the end.
Found this idea in the YT video from some prof (dont remember his name )
But one question: What is “parallel reverb”? I did some googleing but I honestly did not understand the explanation. As I already said, I am very new to recording/producing, so I am sorry if I missed something obvious…
By parallel, I mean a reverb whit which you can choose the balance between wet and dry signal (typically, we’d do this with an aux bus and each track would send to that bus).
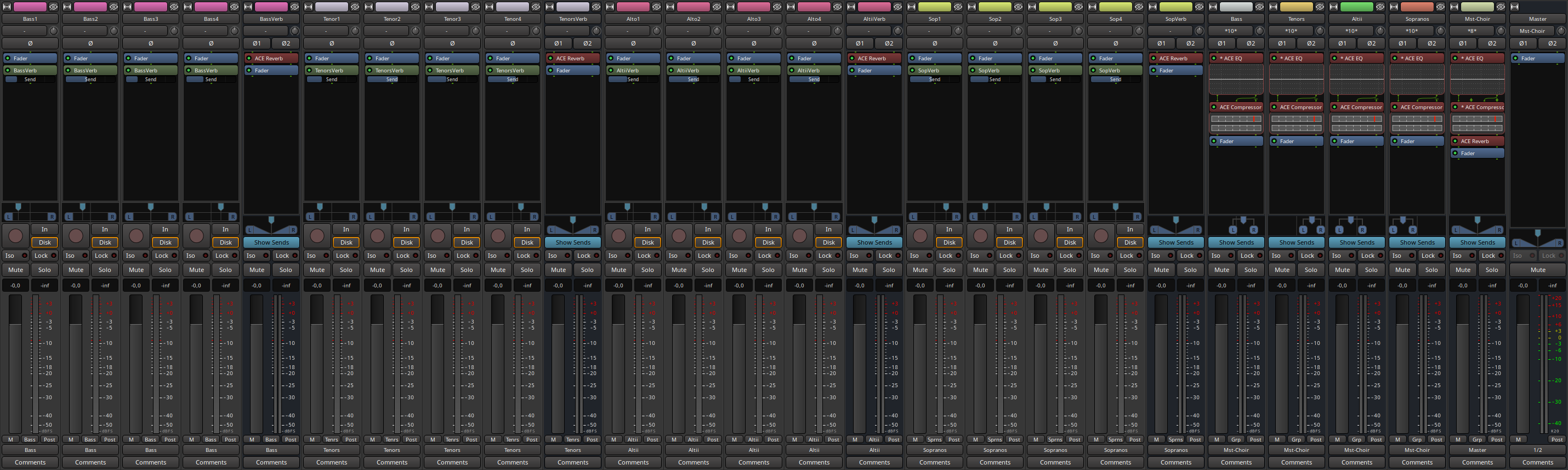
Here is a screenshot of a typical session when I do this (the pan and send value are more or less random here, this is just to showcase what it’d look like).
I hope this helps.
That’s a great illustration, and just to clarify for the original poster: the balance between wet and dry signal for any given voice is adjusted by varying the “send” level that goes from that voice’s track into the reverb bus. The reverb plugin itself would be set to fully wet, and by varying the send levels from each track that feeds into the reverb bus you will get a three-dimensional sense of space, with some singers appearing to be closer to the listener than others, especially if these different reverbs use different pre-delay settings. See for example https://www.sageaudio.com/blog/mixing/how-to-create-depth-and-width-with-reverb-and-delay.php
for each section (i.e. high tenors, low tenors, bariton, bass), i do this:
i create a bus to which i send all the “raw” tracks belonging to that voice. i would probably do some individual eqing on each track to make them sound a bit different. and i would also pan these tracks a bit left and right to simulate people standing at different positions.
i create a second bus that gets the same tracks as “sends”. this bus has a reverb. because i use sends, i can have a different mix (in terms of the volume) of each track in this bus compared to the bus described in #1. the volume of the sends thus only influences the characteristics of the reverb.
the reverb bus then also gets sent to the general section bus.
then of course, combine the different sections, pan them, mix them etc…
Except you would only create a single reverb bus in most cases and send ALL the sections to that one bus. Typically you don’t want to have different reverbs for each section as it would make them sound like they are in different rooms, or you would be updating all the reverbs each time you made a change, adding 4x the work or more for you. This way you can process the bus and modify all the reverb at once or make a single change and change it all.
The Reverb bus would then be routed to the master directly generally, and if you are using VCAs to mix, you can still bring down a section AND it’s reverb would naturally tail off as well.
Not speaking for Eamonn, but I could see, for maximum realism, a rationale for using different reverbs for each section of the choir since they are situated at different distances from the listener – as it’s not just the amount of reverb that varies based on distance, but the nature of the reverb (e.g., reverb time and predelay) as well. In a typical STBA arrangement, the tenors and basses would be farthest away from the listener, with the sopranos and altos closer in on both sides.
Both of those articles appear to have been hastily written and have typos and a few inaccuracies, but they provide a really useful overview of the possibilities.
Yes but if you are going to go into that level of detail, there are multiple ways to address it, and primarily you are looking at different predelay times specifically for what you are discussing, something that can be handled with careful routing, panning, and inserting delay appropriately. And of course appropriate reverbs. Some reverbs even allow you to place within a 3D space to modify this to an extent, though I don’t think I have seen a Linux native one yet.
EDIT: Forgot to address another aspect of this. While you are not incorrect for a ‘traditional’ choir in terms of placement, reality is many choirs don’t follow this (Outside of maybe school choirs) in my experience, and adjust based off the needs of balancing acoustically, fitting the space, etc. Also if you want to be ‘realistic’… for most people the amount of reverb will not change appreciably based off the placement of the person in the space in terms of a choir layout, they will all effectively have the same ‘amount’ of reverb, though some frequencies in the space may be more efficient in reverberation than others, giving an illusion of different voices getting a stronger reverb as those voices go into those frequency ranges, but again other ways to handle that as well.
You are not incorrect, but I would argue that especially if you are starting out, it is better to use a single reverb, it is far more important to have your ‘choir’ sound like it is performing in the same space, than to try to get to a level of detail you may not even be able to truly hear, and increasing your work multiple times. Not to mention the a-reverb in particular is a bit basic to even address that aspect of it, I would suggest other reverbs especially on voice in general.
Pay more attention to your panning, dynamics, timing, and mixing, you will get a good strong result. Neither way is wrong necessarily, but if you are starting out and learning, it is far more important to understand the effect of those things than to go overboard trying to get detail out of the reverb that may not exist. There is a reason I address all of those aspects in the students I teach before I even touch on reverb.